반응형
안녕하세요. 언제나휴일입니다.
이전 게시글에서는 웹 페이지를 수집하는 방법을 알아보았습니다.
1. 웹 수집 로봇
다음이나 네이버, 구글 등의 포탈 사이트에서 제공하는 웹 검색 서비스를 제공하려면 방대한 양의 웹 페이지를 수집해야 합니다.
이러한 작업은 수집할 사이트 주소를 사람이 일일이 전달하는 것은 불가능에 가까운 작업입니다. 초기에 수집할 Seed 사이트는 전달하지만 이 후에 수집할 웹 페이지는 전달할 필요가 없습니다.
웹 수집 로봇은 Seed 사이트를 수집하면 수집한 웹 페이지 내에 있는 링크를 다시 수집할 대상 사이트로 지정하기 때문이죠.
이러한 웹 페이지를 수집하는 로봇을 만들어 봅시다.
2. 테이블 정의
제일 먼저 테이블을 정의하기로 할게요.
(여기에서는 MSSQL로 작업할게요. WebSearchEngine 데이터베이스를 생성한 후 테이블을 추가합시다.)
2.1 Candidate 테이블
수집할 웹 페이지 주소를 기억할 후보 테이블(Candidate)을 정의합시다.
CREATE TABLE [dbo].[Candidate] (
[Id] INT IDENTITY (1, 1) NOT NULL,
[url] VARCHAR (1000) NOT NULL,
[depth] INT DEFAULT ((0)) NOT NULL,
PRIMARY KEY CLUSTERED ([Id] ASC),
CONSTRAINT [UNI_URL] UNIQUE NONCLUSTERED ([url] ASC)
);

수집할 웹 페이지 주소(url)과 seed 사이트에서 상대적 깊이(depth)와 순차적으로 증가하는 일련 번호(id)를 갖습니다.
2.2 WebPage 테이블
수집한 웹 페이지 정보를 기억할 테이블(WebPage)도 정의합시다.
CREATE TABLE [dbo].[WebPage] (
[wid] INT IDENTITY (1, 1) NOT NULL,
[title] VARCHAR (200) NOT NULL,
[url] VARCHAR (1000) NOT NULL,
[description] VARCHAR (MAX) NOT NULL,
[mcnt] INT NOT NULL,
PRIMARY KEY CLUSTERED ([wid] ASC),
CONSTRAINT [TU] UNIQUE NONCLUSTERED ([url] ASC)
);
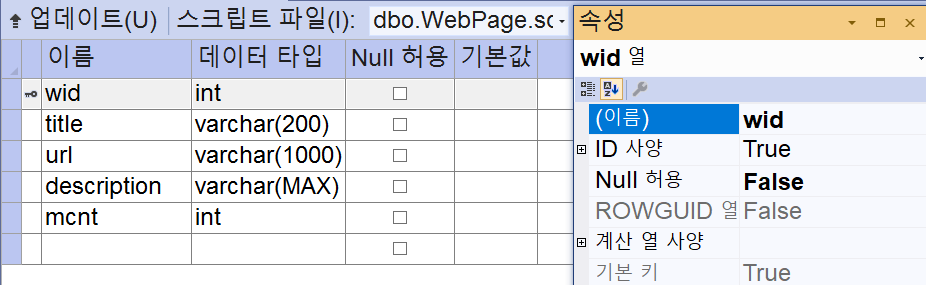
제목(title), 주소(url), 내용(description), 순차적으로 증가하는 일련 번호(wid)를 갖습니다. 그리고 단어수(mctn)를 제공할게요.
반응형
'빅데이터 > 빅데이터 with python' 카테고리의 다른 글
| [빅데이터 python] 웹 수집 로봇 만들기 - 5. CandidateSql 클래스 정의 (0) | 2020.11.16 |
|---|---|
| [빅데이터 python] 웹 수집 로봇 만들기 - 4. WebPageSql 클래스 정의 (0) | 2020.11.16 |
| [빅데이터 python] 웹 수집 로봇 만들기 - 3. WebPage 클래스 정의 (0) | 2020.11.16 |
| [빅데이터 python] 웹 수집 로봇 만들기 - 2. EHHelper 클래스 정의 (0) | 2020.11.16 |
| [빅데이터 python] 웹 페이지 수집하기 (0) | 2020.11.16 |